Deep data analytics for in-field HBM monitoring and repair
As the quest for increased bandwidth and speed continues, multi-die technologies with advanced memory architectures are introduced. Complexity of these heterogenous packaging continues to develop, bringing on new reliability challenges.
proteanTecs introduces a new approach to HBM subsystem monitoring and repair for advanced in-field reliability assurance. By applying analytics to data created by on-chip Agents, proteanTecs’ Proteus™ provides actionable insights and alerts on the system’s lifetime operation. Download the full White Paper here.
What is High Bandwidth Memory (HBM)?
High Bandwidth Memory (HBM) is a specialized form of stacked memory architecture that is integrated with processing units to increase speed while reducing latency, power, and size. It presents a premium DRAM offering for high-bandwidth applications such as next-generation supercomputers, graphics systems, and artificial intelligence(AI).
HBM is rapidly evolving to meet the changing needs of the datacenter and networking industries and the technology has already gained significant adoption in the market, expected to grow at a CAGR of 32% by 2022¹. HBM was adopted by JEDEC² as an industry standard in October 2013 and its second generation, HBM2, was accepted in January 2016.
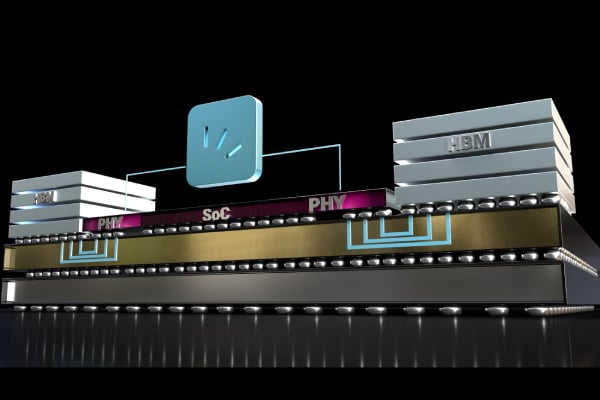
The HBM Reliability Challenge
Visibility of HBM subsystems is limited by nature due to its 3D integration technology, and signal integrity problems are difficult to debug, validate and monitor. Multi-die HBM packaging introduces new reliability challenges which can lead to functional device failures in-field. These technologies are both inherently complex as well as expensive, therefore system failures afflict significant losses on manufacturers and service providers alike.
HBM PHYs do not allow for u-bump redundancies due to the high-density routing, and one u-bump per signal is used for the entire HBM connectivity. A failure in any of the PHY or HBM u-bumps will lead to a chip operational failure. A typical 4xHBM2 includes 13,600 u-bumps for connectivity and the lack of redundancy creates are liability challenge and risk of full HBM subsystem failure. At testing, the implications of a failed module incur significant monetary losses for manufacturers. In lifetime (field) operation, a failure in the HBM subsystem may affect the whole system and lead to an abrupt operational failure and unplanned downtime.
Testing of the HBM subsystem is performed using industry standard detection tools that lack parametric sensitivity so marginal lanes are not detected. These may lead to degradation over time and ultimately failure during lifetime operation. Furthermore, detecting faulty lanes requires activation in test mode, therefore degradation over time in mission-mode is not monitored.
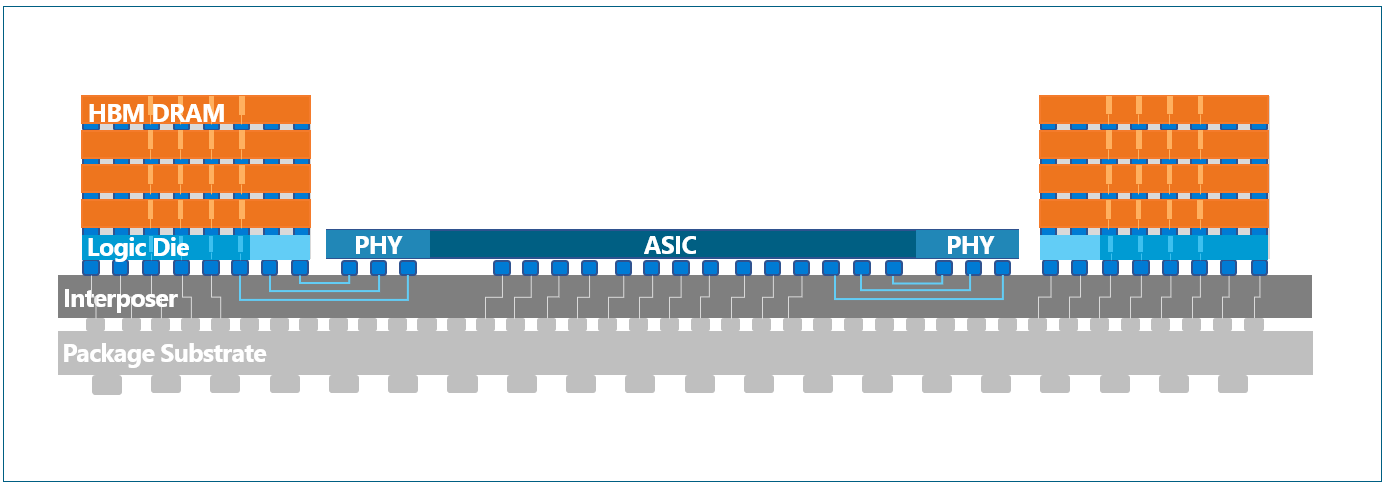
Proteus™ In-Field Reliability Monitoring
proteanTecs’ Proteus™ introduces visibility to HBM, mitigating the inherent limitations and complexities of heterogeneous packaging. Proteus is a one-stop software platform which applies analytics to data created by on-chip Agents™ (IPs), custom tailored to represent and automatically cover a specific design. By continuously monitoring signal integrity, Proteus provides actionable insights for reliability monitoring and repair, per pin and in mission mode, to detect degradation trends.
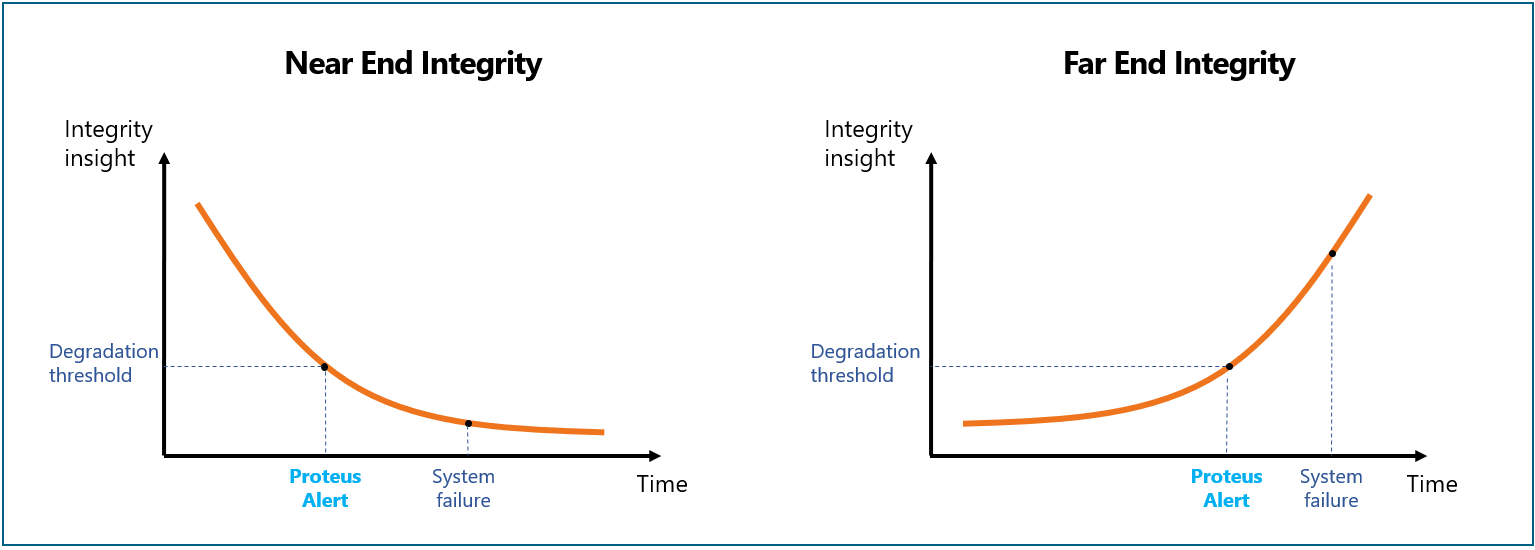
Proteus provides a new method of correlating lane degradation to Far-End (FE) and Near-End (NE) insights, which are a function of ASIC and DRAM driver strength, NE and FE micro-bump integrity, Rx sensitivity and interposer.
By alerting on marginal performance of Near-End or Far-End signals, service providers can perform Predictive Maintenance. Proteus identifies potential candidates for faulty-lane replacement and provides the information to the Lane Repair mechanism, which replaces marginal lanes with redundant ones at scheduled maintenance cycles. This enables prevention of system failure due to signal quality degradation beyond margin limits.
At system bring-up and characterization, Proteus enables virtual probing of the signal amplitude and slew-rate for each pin, serving as an embedded “scope”, without impacting the measured signal. This provides visibility of HBM signal parameters per pin during system characterization and validation, reducing time-to-market, achieving product optimization and increasing confidence in ramp-up.
As the complexity of heterogenous packaging continues to develop, Proteus offers a revolutionary approach to HBM in-field monitoring,for unprecedented reliability assurance. Service providers now have the visibility they need to perform predictive maintenance, detecting and repairing faults in systems before they become failures.
To learn more watch the webinar 2.5D Packages: How to Monitor Today So They Don’t Fail Tomorrow - A GUC 7nm HBM Controller ASIC Use Case, featuring GUC's CTO Igor Elkanovich
Sources:
¹ Market Reports World: High-bandwidth Memory Market 2019 Research
² https://www.jedec.org/standards-documents/docs/jesd235a


