%20(1).jpg)
From Preventive to Predictive Maintenance
Data is Indeed ‘The New Oil’
Data has become the most valuable resource of our time, with processing, storage and networking being the key assets of the modern digital world. This has fueled a two-decade spread of massive datacenters around the globe and a surge in the cloud services they offer people, corporations, and countries alike.
New services like video, game streaming, AI and social media push the need for datacenters to new highs, not to mention the promise of a smart connected world enabled by edge computing and 5G.
Who Manages the Datacenter’s Data?
For datacenters there are two things that keep stakeholders awake at night; hackers and unexpected downtime. The first can cause the latter, however, unplanned downtime can occur through hardware failure, without the help of a hostile third-party security breach. Needless to say, datacenters pour huge resources into preventing self inflicted harm. And it should come as no surprise, given a three-second server dropout is all it takes to have Facebook make the front page of the New York times. That’s not the kind of PR your shareholders want to be waking up to in the morning papers.
The Uptime Institute’s 2019 datacenter survey showed that 34% of respondents reported some form of an outage or serious service degradation in the past year, with severe financial consequences - some costing more than $1 million. So, without considering the cost associated with a tarnished brand, it is apparent there is a need for a clear-cut solution to ensure uptime.
With such high stakes in play and when seconds translate to millions in losses, datacenters have an overwhelming burden of responsibility to the clients they serve.
Such is the industry anxiety around this, entire websites like downdetector dedicate themselves solely to the task of offering datacenter clients minute-by-minute visibility and real-time outage alerts. Hence, they call themselves the “weather report” for the internet.
If data availability is to maintain a competitive edge in such unforgiving market conditions, it will do so by eliminating any potential for dreaded downtime debacles.
The Cost of Resilience & Redundancy Overflow
Such a high level of availability, expected at 99.995%, does not happen naturally or by chance; it is a result of careful forward planning, sophisticated topologies, and routine maintenance procedures.
With an absolute imperative to avoid service downtime at any cost, almost any cost is invested in redundancy and resilience strategies that inflate over time with mounting expenses of hyper-caution.
Before we examine just how it’s possible to defuse the problem and strip out cost, it’s worth pinning down exactly what redundancy and resilience mean for datacenters.
Redundancy – refers to the level of backup equipment a datacenter must deploy in case the primary systems or network fails.
Resilience – refers to a datacenter’s ability to continue operating when there has been equipment failure or anything else disrupting normal operation.
The relationship between these two intertwining strategies is simple; the more redundancy the datacenter has in place, the more resilient it will be. Putting it another way, if the system can survive a failure of one or more individual components - it is resilient. The commonality between the two is also straightforward; they’re both ‘when’ strategies.
- ‘When the primary equipment or infrastructure fails’ (redundancy)
- ‘When there has been equipment failure’ (resilience)
The implicit problem here is one of assumptions. ‘When’ strategies assume things will go wrong and merely patch a problem there isn’t yet a root answer for. In the case of data availability, this means eye-watering investment in second-tier, ‘standby’ equipment only active during downtime situations, and routine servicing and maintenance of primary and backup hardware.
Although these safety-net processes are an indispensable part of datacenter feasibility and market value proposition, resilience and redundancy become self-defeating when left to accrue costs almost on a par with the very expenses of downtime they try to prevent.
Enter predictive maintenance.

Deep Data Analytics
proteanTecs provides datacenters a way to track the health and performance of the electronic fleets, not just retrospectively but proactively.
Ultimately, maintenance takes on a predictive perspective that gives systems (e.g. servers and switches) an active role in reporting on their own health metrics. This is performed using a combination of in-system monitors, data analytics and artificial intelligence.
proteanTecs provides Universal Chip Telemetry™ (UCT) which enables high coverage visibility of electronic systems in production and in the field. Chip telemetry plays an important role in measuring predictive maintenance by monitoring key parameters’ functionality and reporting on critical issues. These include performance degradation due to aging or latent defects, sub-optimal load distribution or effects of environmental conditions.
By gaining visibility into the internal events throughout the system’s operational use, datacenter operators are alerted on faults before failures, thus enabling them to tailor maintenance activities accordingly.
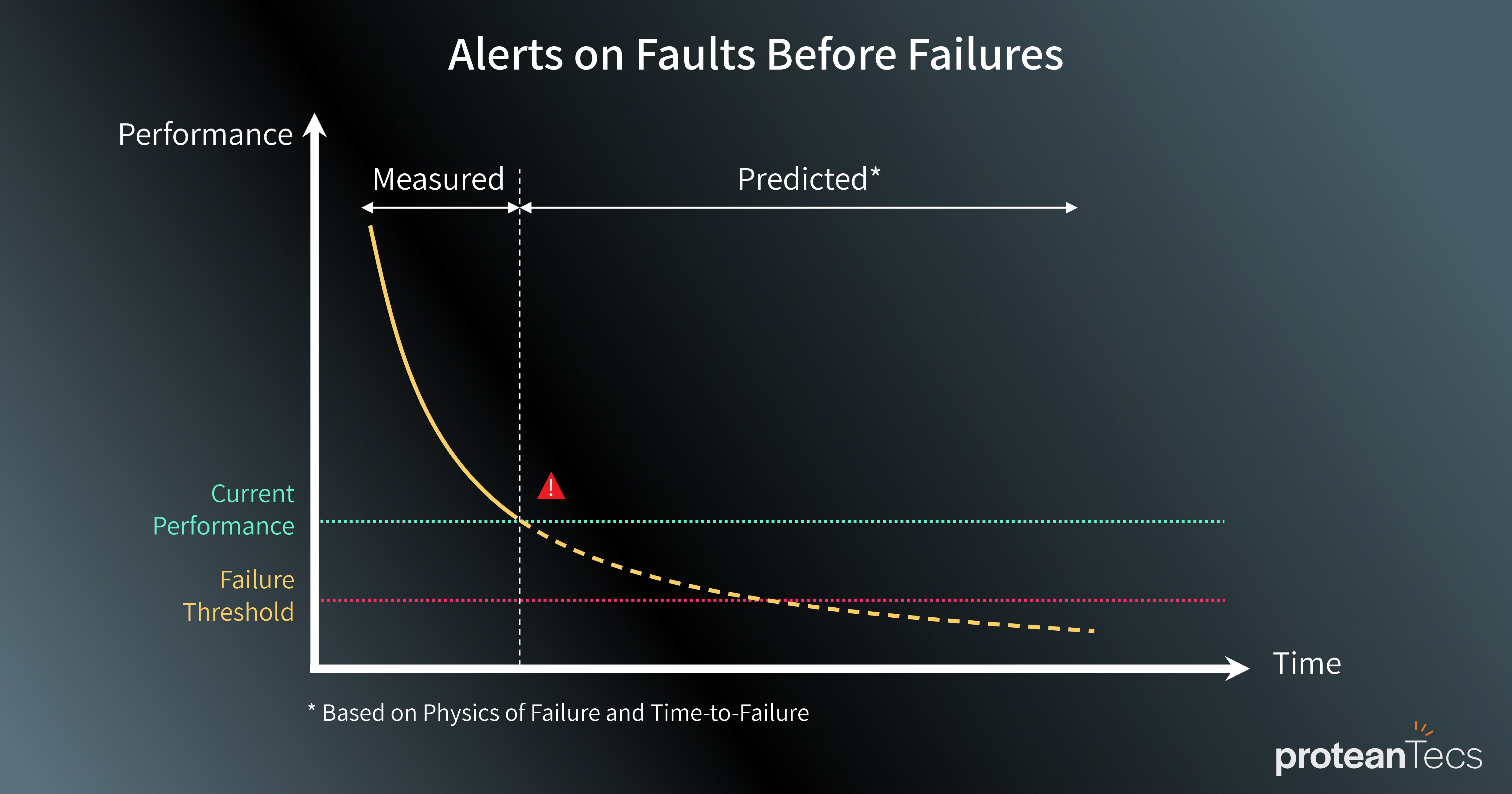
Predictive maintenance is not only set to overhaul how datacenters think about redundancy and resilience planning. A predictive approach also allows operators to optimize data traffic load balancing, extend product lifetime by optimizing performance, and reduce RMAs (return material authorization).
Already employed in manufacturing processes, the global predictive maintenance market is set to witness a healthy CAGR of 29.22% by 2026. It is only a matter of time before datacenters adopt this way of thinking to make downtime a thing of the past.


